微博注册了个小号,为了看看都是什么牛鬼蛇神在微博里推送信息流广告,尝试抓取一下。
虽然有YAWF(Yet Another Weibo Filter)这样好用的脚本可以屏蔽广告,但屏蔽了就看不到了。
找到 API 接口
F12 切换到 Network,在首页刷新页面,筛选捕捉到 api 接口https://weibo.com/aj/mblog/fsearch。
新建标签页访问,去掉不必要的参数(包括一堆用来指定上下文区间和已读分界线的 id),只留下必要的部分。
然后直接上代码开始爬取内容:
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:64.0) Gecko/20100101 Firefox/64.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'DNT': '1',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'Cache-Control': 'max-age=0',
'Cookie': cookie
}
params = (
('ajwvr', '6'),
('pre_page', '0'),
('page', '1'),
('pagebar', '0'),
)
response = requests.get('https://weibo.com/aj/mblog/fsearch',
headers=headers, params=params)
返回数据是 json 结构,在data字段里存放了页面内容,这里用 lxml 库解析,保存 html 文件进行下一步。
import json
from lxml import etree
result = json.loads(response.content)
html = etree.HTML(result['data'])
with open('feed.html', 'w', encoding='utf-8-sig') as f:
f.write(etree.tostring(html, encoding='unicode'))
CSS 筛选广告内容
打开保存的 html,格式化一下代码,找到存在feedtype="ad"属性的节点(因为不是每次获取都会有信息流广告,所以可能需要获取很多次)。
然后继续往下看子节点,直到找到具体的微博链接:
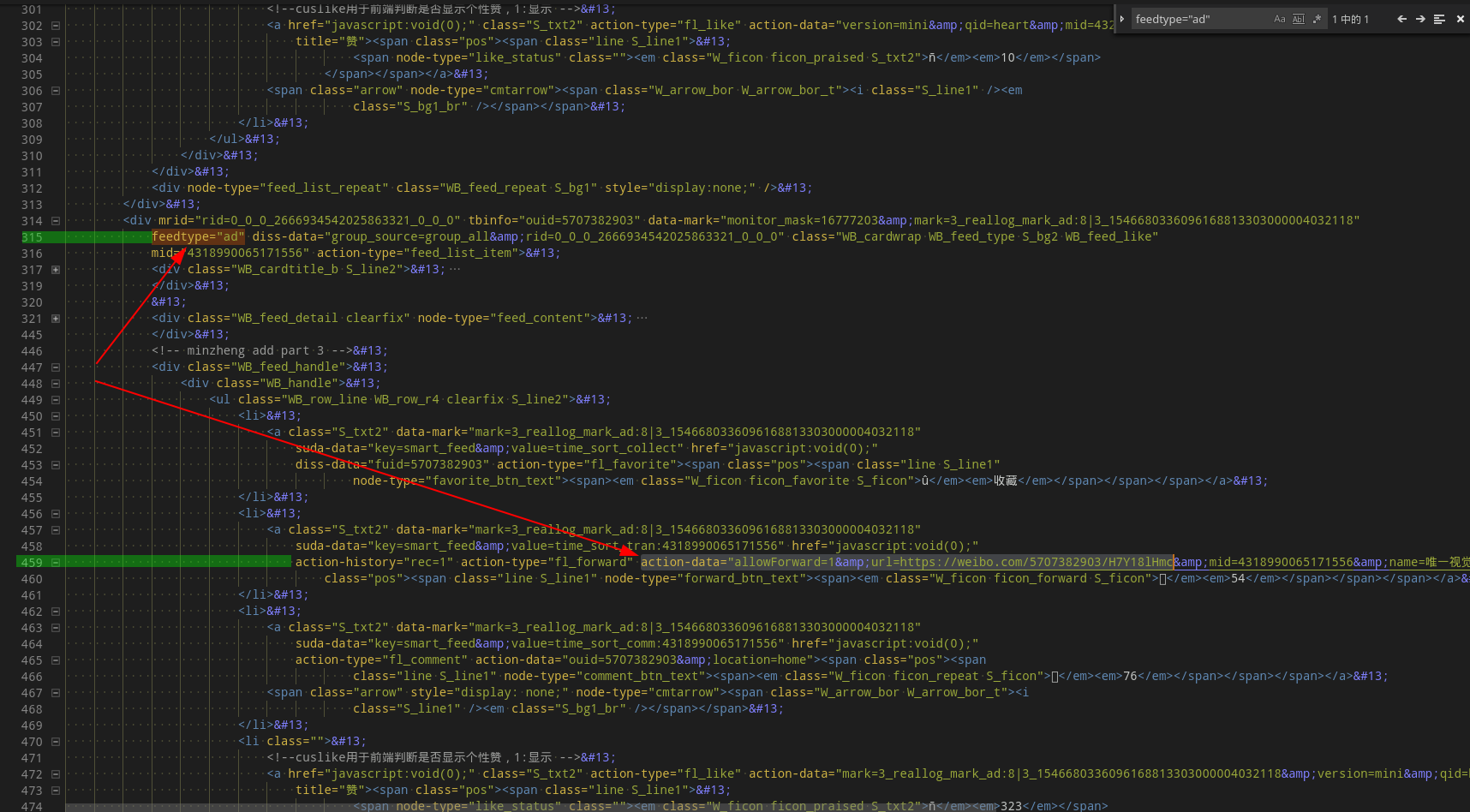
获取此节点的 xpath:"//div[@feedtype]//a[@action-history='rec=1']/@action-data"
结合正则表达式提取链接:
import re
html = etree.HTML(result['data'])
links = html.xpath("//div[@feedtype]//a[@action-history='rec=1']/@action-data")
for link in links:
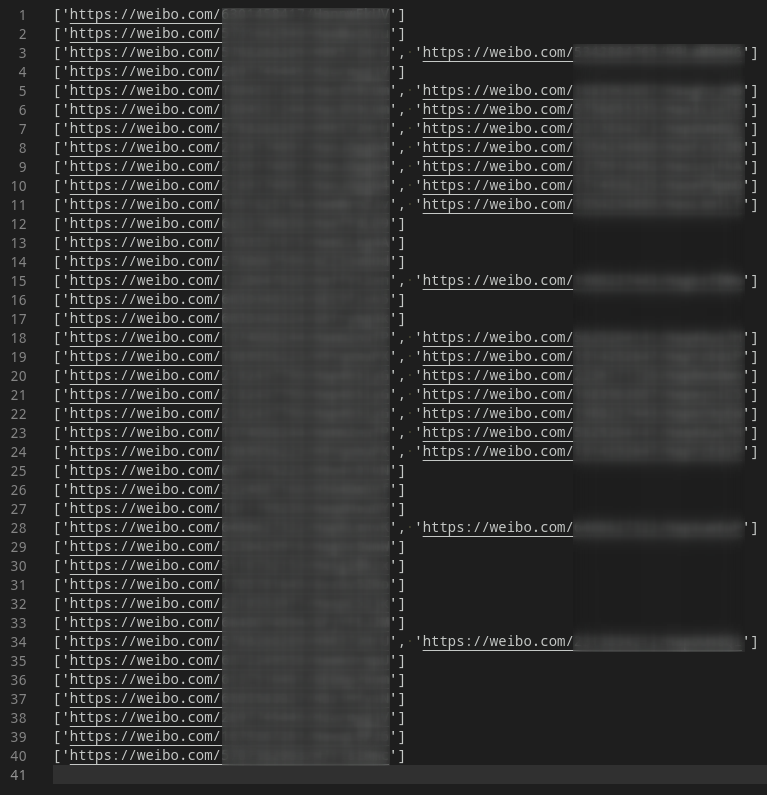
adver = re.findall(r'url=([^&]+)&', link)
with open('adver.list', 'a', encoding='utf-8-sig') as f:
f.write(str(adver)+'\n')
最后通过 crontab 设置成定时任务自动监测。
* * * * * python weibo_adver.py
自动更新 cookie
高频率的连续访问可能会造成微博提示帐号异常,而且运行时间久了 cookie 也会过期,需要自动重新登录获取 cookie。
微博的自动登录轮子很多,不用自己另写。cookie 过期的判断就比较粗暴了,如果读取返回的 json 抛出异常,就可以认为是 cookie 过期造成的。
另外测试发现,不带 cookie 的 api 访问是会返回正常的 json 数据的(但不包含 html 内容)。
import os
def login(username, password):
"""somecode balabala"""
with open('cookies','w') as f:
f.write(cookies)
def main():
if os.path.exists('./cookies'):
with open('./cookies', 'r') as f:
cookie = f.read()
else:
return False
"""somecode balabala"""
response = requests.get('https://weibo.com/aj/mblog/fsearch',
headers=headers, params=params)
try:
result = json.loads(response.content)
except json.decoder.JSONDecodeError:
login(username, password)
return False
"""somecode balabala"""
if __name__ == "__main__":
main()
EOF
就结果而言效果还不错,但也发现信息流广告里还会有一些关注了的博主的正常微博内容,可以考虑和自己的关注列表对比来筛除。